One approach inspired by human learning is through better priors or a world model. Intuitively, a human while learning to drive doesn’t rely solely on trial-and-error, but constructs an internal model of the car and its dynamics. Precise motor control was a relatively recent development in mammals alongside internal modeling, and may be key towards learning effective motor control.

The success of combining planning and learning in Monte Carlo Tree Search (MCTS) approaches has been shown in AlphaZero. Famous successes with AlphaZero have been in games such as Chess and Go, where there is a clean reward signal, and the state space is discrete. However, real-world robotic control problems often have a continuous action space with the presence of continuous noise. Can AlphaZero be used for learning optimal low-level controls?
The problem
CartLatAccel is a simple 1D controls environment with added realistic noise and trajectory following. This task is a very simple, vectorized cart dynamics environment for testing RL driving controls.
First, we use an MCTS online planner on the simple continuous toy problem. Then, we use MCTS search to train a value and policy network. This approach is similar to RL methods such as PPO with an actor and value network, except our loss is now supervised from MCTS training. The search and learning no longer happen simultaneously, since we use a good search mechanism combined with a policy which is able to generalize and guide the search.
We experiment with on-policy MCTS and value net learning, combining both planning and learning to find the optimal car lateral control.
Online planning
The first step was implementing vanilla MCTS for online planning. Online planning means before each step, we runm simulations from the current state and pick the best action which maximizes our expected returns Q(s,a). We modify MCTS to work with continuous action spaces. We can test this with a simple counting game where the goal is to get as close to 10 as possible and our actions are continuous from (-1,1).
For the simple CartLatAccel problem, we find that online MCTS (depth = 10, n_{sims} = 100) produced competitive results to a 32-layer MLP learned from PPO. MCTS achieved a reward of -3.81 compared to -3.45 using PPO running 100 steps.
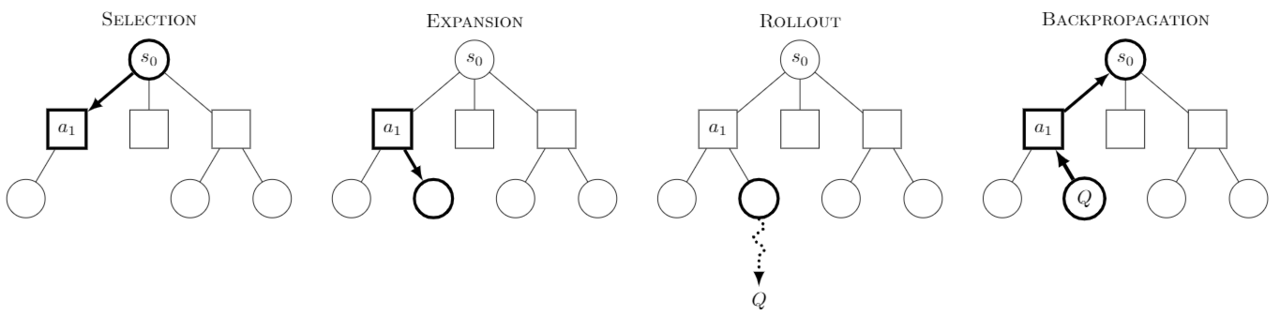
AlphaZero for Continuous Control
We use the AlphaZero training procedure to learn a NN policy from MCTS. This can then be executed on a car without the need for real-time planning. We iteratively develop and test the value net and policy net with MCTS individually, before combining them into the final training.
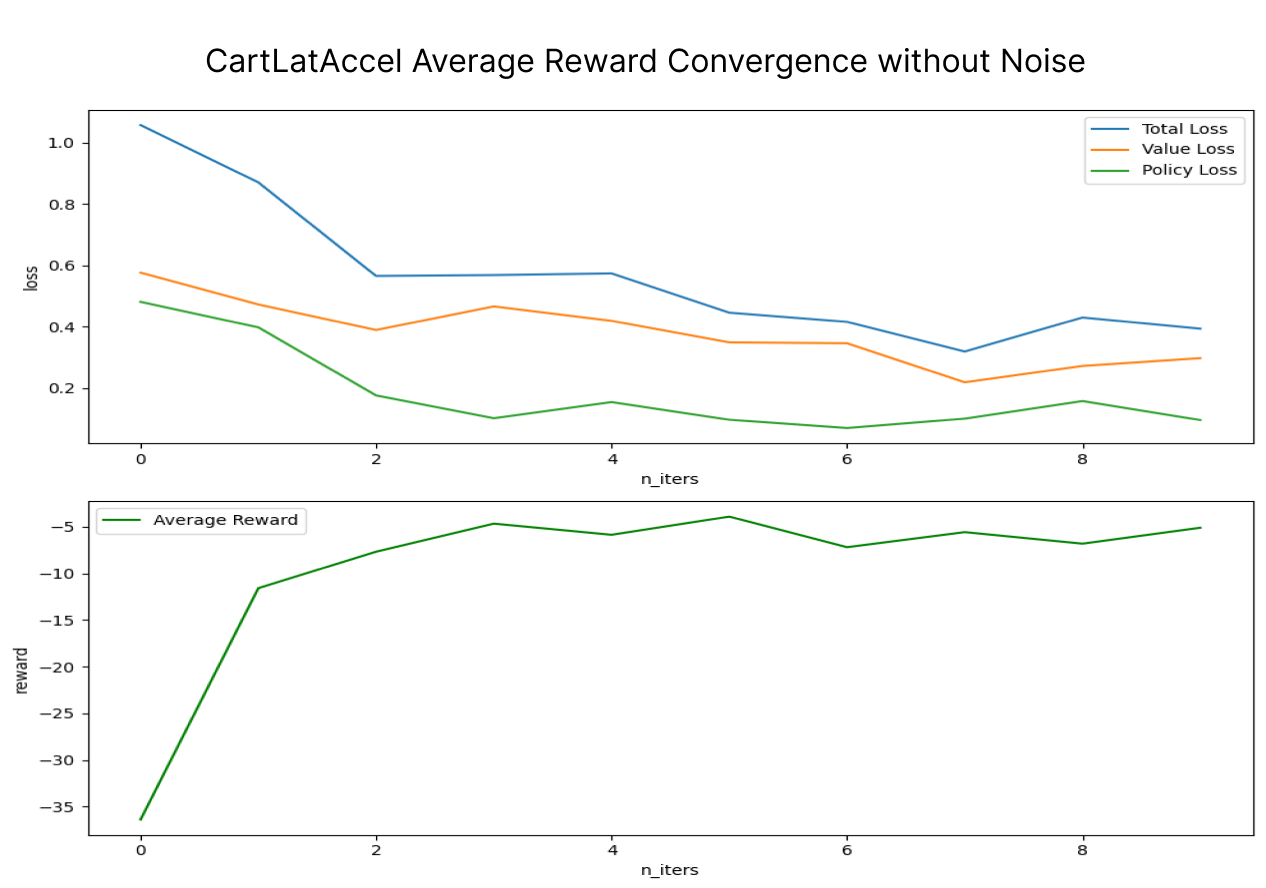
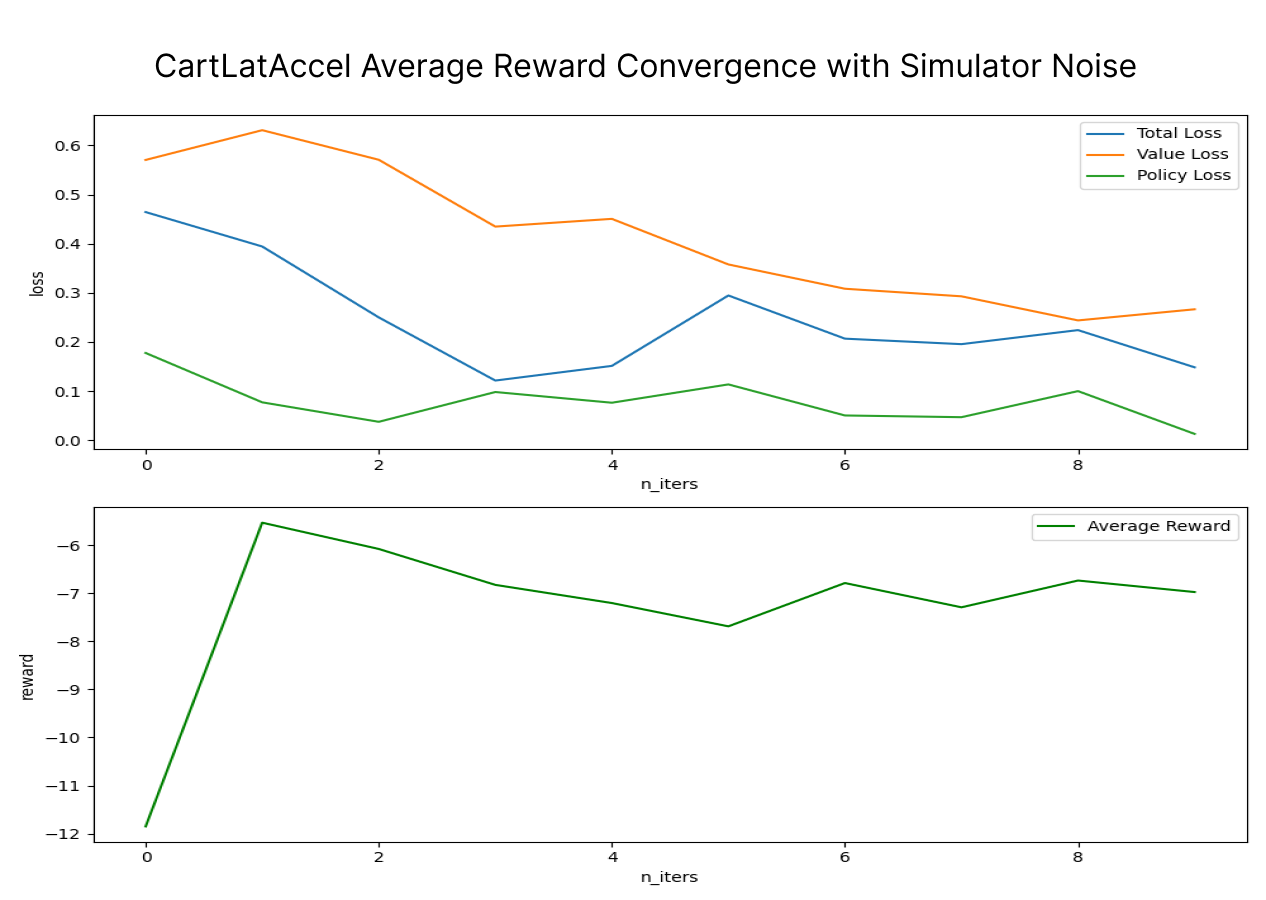
We find that AlphaZero beats PPO on the toy problem, achieving higher reward and lower variance of -5.52 (std 1.92) compared to -6.52 (std 2.44) over 10 evaluation runs. When noise is applied to the task, AlphaZero remains robust under noisy conditions (-6.52 std 2.44). Using MCTS helps lead to more reliable training targets, as it helps provide signal towards better simulated policies and stabilizes learning under noisy conditions. Learning and planning can find a more optimal solution, but is generally much slower, taking 200x longer for a similar number of steps.
Next steps
AlphaZero shows promising results on the controls task, achieving more stable learning and higher rewards than PPO. The next step is to apply AlphaZero to the controls challenge with more complex realistic noise. This is a much harder challenge and requires keeping track of intricate temporal correlations as context into the simulated car.
It’s unclear whether this approach will scale well to the challenge. However, if successful, we might find that the methods which led to the evolution of a grandmaster can also pave the way toward superhuman performance in autonomous driving. Combining planning and learning may be a step to useful autonomous robots capable of navigating the complexities of the real world.
]]>